Comment extraire le texte depuis un PDF?

Résumé
Vous souhaitez extraire facilement le texte d’un PDF? Ce guide vous présente des méthodes simples et efficaces, des outils gratuits aux solutions OCR avancées. Gagnez du temps et transformez vos PDF en texte modifiable en quelques clics. Découvrez vite nos conseils !

Table des matières


Étapes pour copier et coller le texte page par page


La copie du texte d’un PDF entraîne des caractères déformés
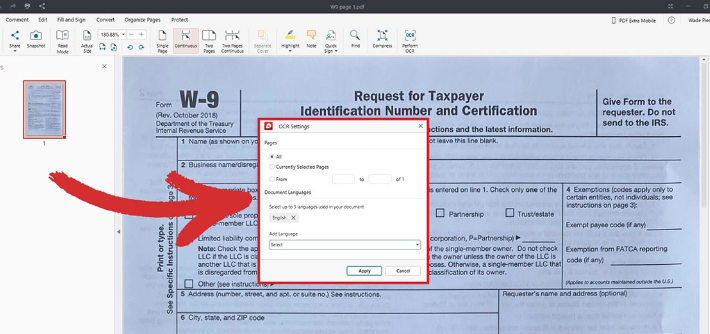
Fichiers PDF numérisés

Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
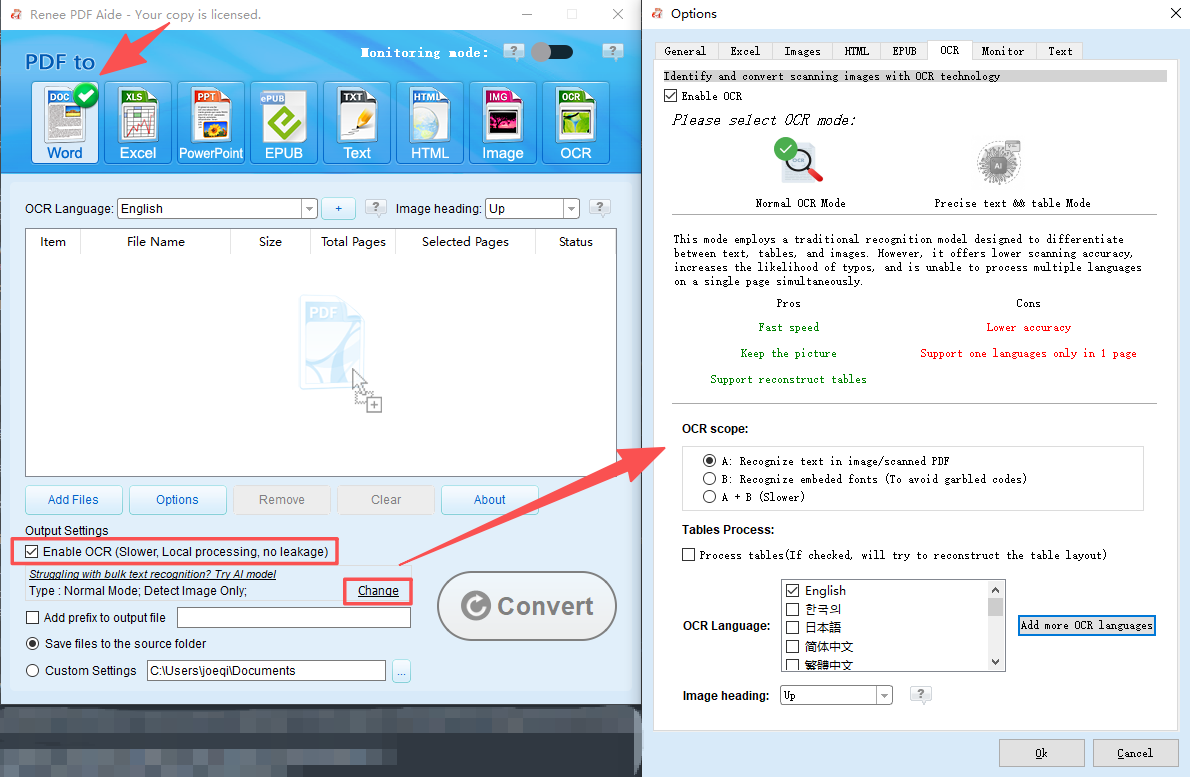
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Comment utiliser l'IA pour l'extraction de texte
Extract all text from this image and do not summarize the text.
Extract all text from this pdf file.

Dans de nombreux cas, les utilisateurs doivent faire des captures d’écran manuellement, page par page, ce qui est long et sujet aux erreurs. Pour des charges de travail plus importantes ou un usage professionnel, un logiciel de bureau dédié reste le choix le plus fiable et le plus efficace.
🗓️ Gestion des PDF: Formules gratuites vs payantes (Mise à jour 2025)
| Plateforme | Version gratuite | Version payante / Premium | Prise en charge de la conversion PDF | Formats de sortie | Améliorations IA-OCR 2025 |
|---|---|---|---|---|---|
Microsoft Copilot | Téléchargez des PDF jusqu'à 50 pages ; divisez les fichiers volumineux. S'intègre avec Edge pour une OCR rapide. | Microsoft 365: Pages illimitées, extraction de tableaux assistée par IA. | ❌ Pas de conversion directe, mais exporte en JSON via API. | Texte brut, JSON | Cognitive Services v3.1: 98% de précision pour les documents numérisés. |
ChatGPT (OpenAI) | Pas de téléchargement direct ; collez du texte ou une capture d'écran. | Plus/Team: Téléchargez jusqu'à 300 pages ; OCR automatique pour les images. | ❌ Résume uniquement ; utilisez des plugins pour exporter. | Texte brut, listes à puces | Intégration LlamaParse: Gère les PDF multilingues (par ex. anglais+hindi). |
Grok (xAI) | Téléchargez ~50 pages ; recherche sémantique pour le texte. | Premium: ~200 pages, traitement par lots. | ❌ Texte brut uniquement. | Texte brut | OCR améliorée pour les numérisations de faible qualité ; axé sur la confidentialité. |
Qu'est-ce que Renee PDF Aide ?
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Extraire le texte vers Word
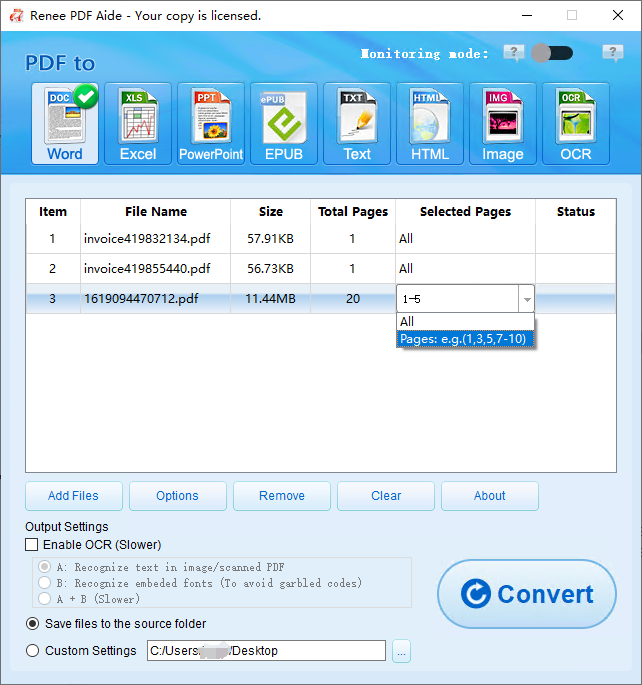

Extraire le texte vers Excel
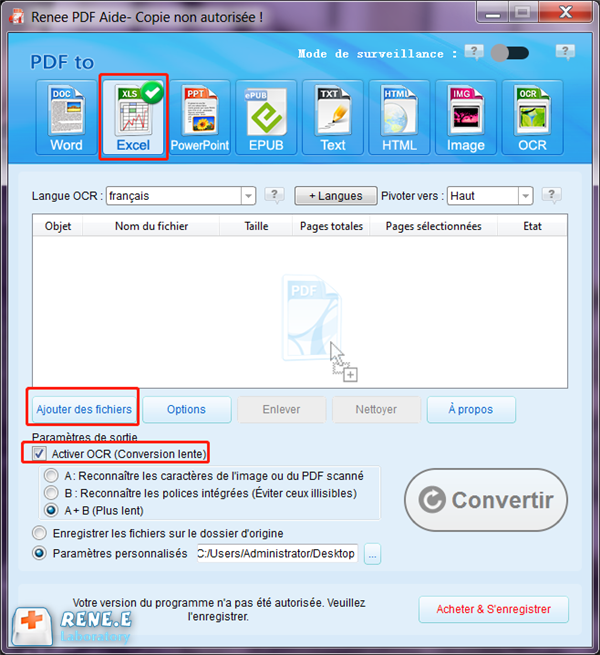
Extraire le texte vers PowerPoint
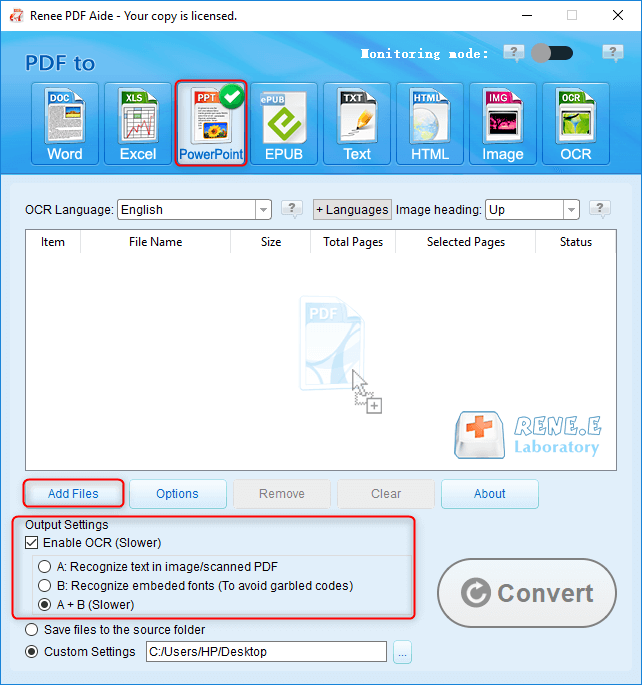
Extraire le texte vers TXT
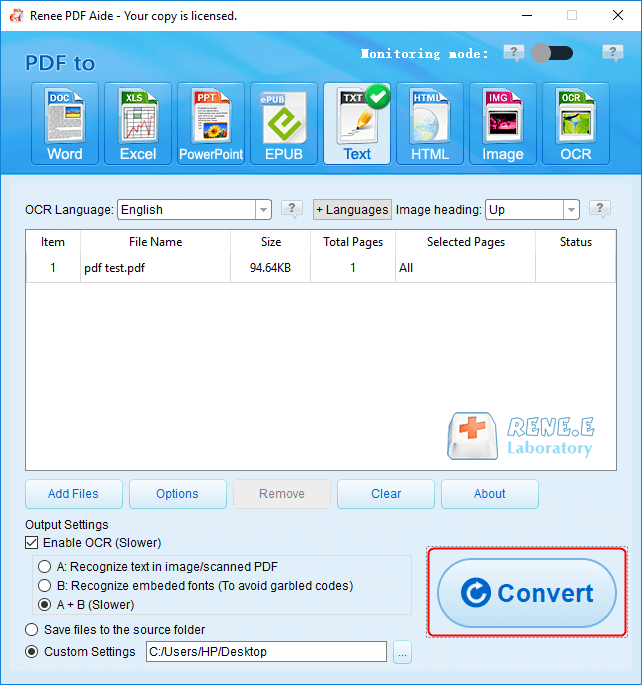

| Outil | Fonctionnalités | Limitations |
|---|---|---|
PDF Candy | Conversion gratuite de PDF vers TXT, OCR automatique pour les fichiers numérisés, interface conviviale. Idéal pour extraire des listes de produits de catalogues. | Limites de taille de fichier (~100 Mo), publicités dans la version gratuite, plus lent pendant les heures de pointe, risques de confidentialité dus aux téléchargements sur serveur. |
PDF2Go | Aucune inscription requise, prend en charge les mobiles, conversion rapide en TXT avec OCR. Idéal pour prendre des notes rapides à partir de PDF de réunion. | Taille de fichier limitée, exposition potentielle des données, perte occasionnelle de mise en forme, connexion internet requise. |
Exemple de script Python
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Page {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Page {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Format de sortie non pris en charge. Utilisez 'txt' ou 'docx'.")
return output_file
except Exception as e:
print(f"Erreur lors du traitement du PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Texte extrait vers: {result}")✅ Avantages: Gratuit, personnalisable
❌ Inconvénients: Nécessite une configuration
hin+eng pour une OCR précise. Enregistrez en TXT pour du texte brut ou en Word pour une édition formatée.| Type d'utilisateur | Meilleure méthode | Avantages | Prochaine étape |
|---|---|---|---|
Débutant | Copier-coller ou Outils en ligne | Simple, sans coût ni compétences requises. | Ouvrez votre PDF dans Foxit Reader dès aujourd'hui. |
Professionnel | Renee PDF Aide | Conversions rapides vers Word/Excel, sécurisé et hors ligne. | Téléchargez la version d'essai depuis le site officiel. |
Technophile | Python avec OCR | Automatisé, évolutif pour les big data. | Installez les dépendances et testez le code. |
Utilisateur mobile | Assistants IA | Fonctionne n'importe où avec une connexion internet. | Essayez ChatGPT Plus pour les téléchargements. |
Que faire si le texte extrait est déformé ou incomplet ?
Les outils en ligne sont-ils sûrs pour les PDF sensibles ?
Puis-je extraire du texte de PDF chiffrés ?
Comment gérer les PDF volumineux (par exemple, plus de 500 pages) ?
Comment extraire du texte de PDF multilingues ?
hin+eng) pour une extraction précise à partir de PDF bilingues.L'extraction de texte conserve-t-elle la mise en forme originale du PDF ?
Articles concernés :
Extraire du texte d’un PDF vers Excel : Guide Complet pour Maximiser vos Données

24-04-2025
Mathilde LEROUX : L'article propose un guide complet pour extraire des données textuelles des PDF vers Excel, en abordant les défis...
Comment extraire le texte depuis un PDF?
03-10-2025
Louis LE GALL : Vous souhaitez extraire facilement le texte d’un PDF? Ce guide vous présente des méthodes simples et efficaces, des...
Comment extraire le texte depuis un fichier PDF ?

29-03-2021
Adèle BERNARD : PDF, appelé aussi Portable Document Format, est largement utilisé dans la vie quotidienne. Par exemple, beaucoup des modes...
AVX OCR: La solution clé pour améliorer Renee PDF Aide
25-08-2025
Adèle BERNARD : Découvrez comment la technologie AVX OCR booste la rapidité et la précision de Renee PDF Aide. Vérifiez en...


Commentaires des utilisateurs
Laisser un commentaire