Convertir des PDF en DOCX avec Python: scripts batch, bibliothèques et outils fiables

Résumé
Vous voulez convertir automatiquement des PDF en DOCX avec Python? Cet article passe en revue les meilleures bibliothèques (pdf2docx, PyMuPDF) et des logiciels dédiés. Vous y trouverez aussi des exemples de traitement par lots, l’intégration de l’OCR et la surveillance de dossiers pour automatiser vos conversions de bout en bout.


| Type de problème | Cause typique | Vérification préalable / Diagnostic |
|---|---|---|
PDF numérisés | Pas de texte sélectionnable | Ouvrez le PDF et essayez de sélectionner le texte ; si rien n’est mis en surbrillance, l’OCR est nécessaire |
Tableaux/mises en page complexes | pdf2docx n’a pas de moteur de mise en page | Convertissez d’abord une page et vérifiez les colonnes décalées |
Polices intégrées / texte brouillé | Sous-ensemble de polices ou encodage non standard | Recherchez dans le DOCX des symboles □ ou aléatoires |
Plantes de traitement par lots volumineux | Conflits de mémoire ou de dépendances | Testez avec 5 à 10 fichiers ; surveillez l’utilisation de la RAM |

| Approche | Idéal pour | Limitation clé |
|---|---|---|
pdf2docx | Conversions rapides de PDF numériques | Faible avec les mises en page complexes ; pas d’OCR |
PyMuPDF + python-docx | Contrôle total et logique d’extraction personnalisée | Nécessite un codage important pour la reconstruction de la mise en page |
pdfplumber | PDF centrés sur les tableaux | Pas de sortie DOCX ; extraction de texte uniquement |
Pandoc | Pipelines scriptables ; flux de travail multi-formats | La qualité PDF→DOCX dépend des lecteurs LaTeX/PDF |
LibreOffice CLI | Automatisation par lots ; conversion sans interface | La fidélité de la mise en page varie ; pas d’OCR |
| Fonctionnalité | Prise en charge |
|---|---|
Direct PDF→DOCX | Oui |
OCR | Nonn |
Polices intégrées | Partielle |
Mises en page complexes | Modérée |
Automatisation | Oui |
Formulaires XFA | Nonn |
| Fonctionnalité | Prise en charge |
|---|---|
Direct PDF→DOCX | Nonn (codage manuel) |
OCR | Nonn (OCR externe nécessaire) |
Polices intégrées | Lecture seule |
Mises en page complexes | Contrôle élevé, manuel |
Automatisation | Excellent |
Formulaires XFA | Non |
| Fonctionnalité | Prise en charge |
|---|---|
Direct PDF→DOCX | Nonnnn |
OCR | Nonnnn |
Polices intégrées | Nonnnn |
Mises en page complexes | Bon pour les tableaux |
Automatisation | Oui |
Formulaires XFA | Nonnnn |
| Fonctionnalité | Prise en charge |
|---|---|
Direct PDF→DOCX | Oui (via LaTeX) |
OCR | Nonnn |
Polices intégrées | Nonnn |
Mises en page complexes | Limité |
Automatisation | Excellent |
Formulaires XFA | Nonnn |
| Fonctionnalité | Prise en charge |
|---|---|
Direct PDF→DOCX | Oui |
OCR | Nonn |
Polices intégrées | Partielle |
Mises en page complexes | Modérée |
Automatisation | Excellent |
Formulaires XFA | Nonn |

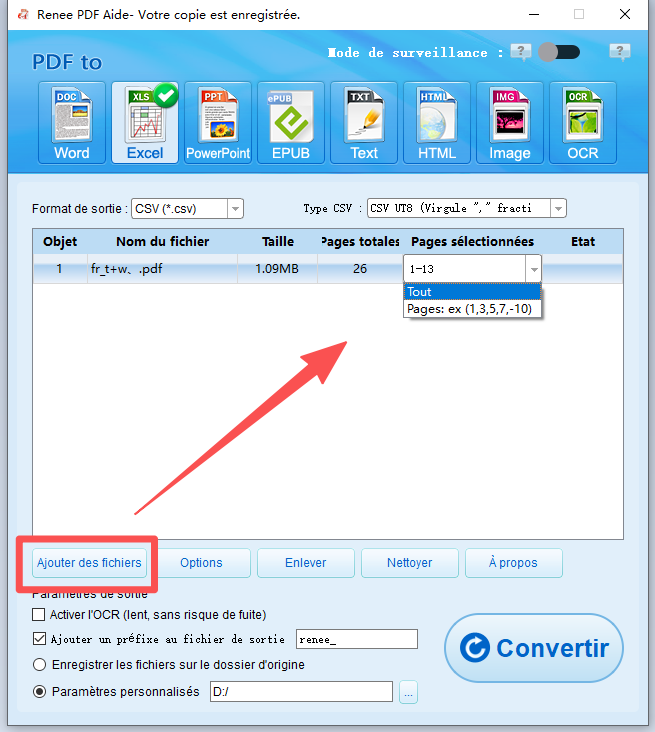
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
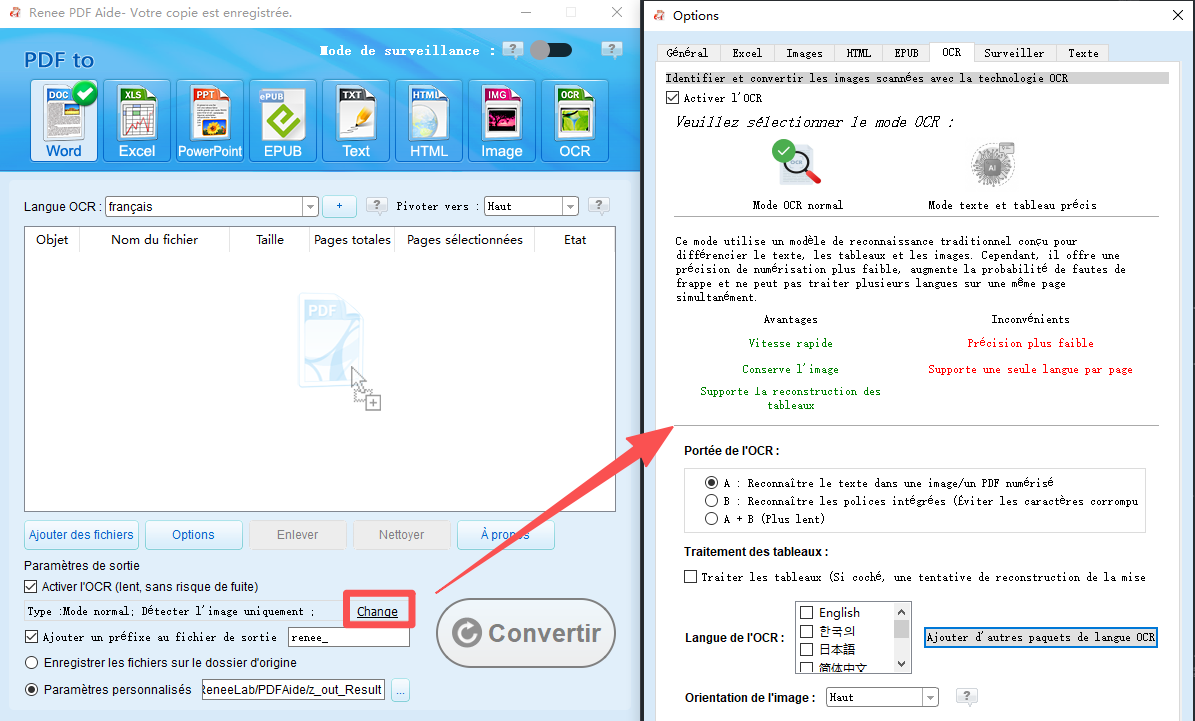
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Principaux avantages
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Étapes
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Limites
- Contrôle total et personnalisation du code
- Gratuit pour les PDF natifs simples
- Intégration facile dans les pipelines Python existants
Cons:
- Pas d’OCR intégrée pour les documents numérisés
- Les tableaux et images complexes sont souvent mal alignés
- Nécessite des outils externes pour l’exécution planifiée
- Un débogage important est nécessaire pour différentes mises en page PDF
| Cas d’utilisation | Outil recommandé |
|---|---|
Test rapide sur 1 à 2 PDF simples | Script Python pdf2docx |
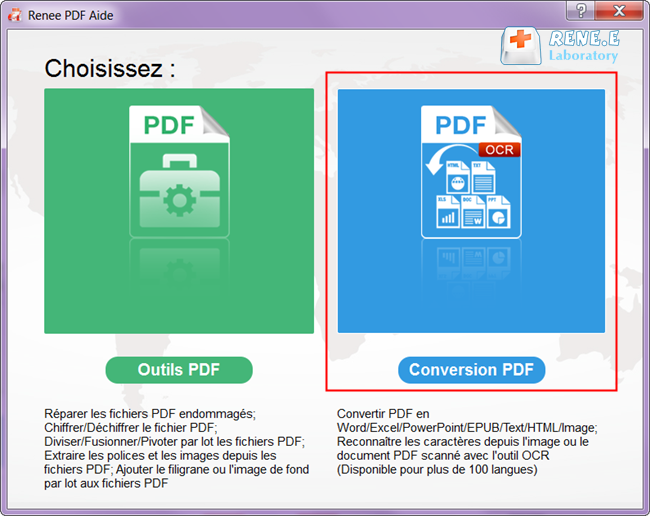
PDF numérisés ou mises en page complexes | Renee PDF Aide avec OCR |
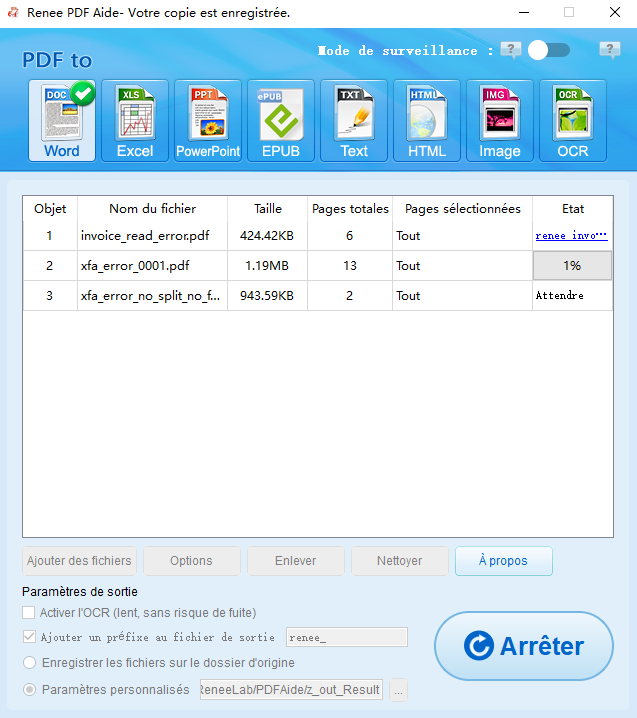
Conversion par lots (plus de 50 fichiers) | Renee PDF Aide (lot + mode surveillance) |
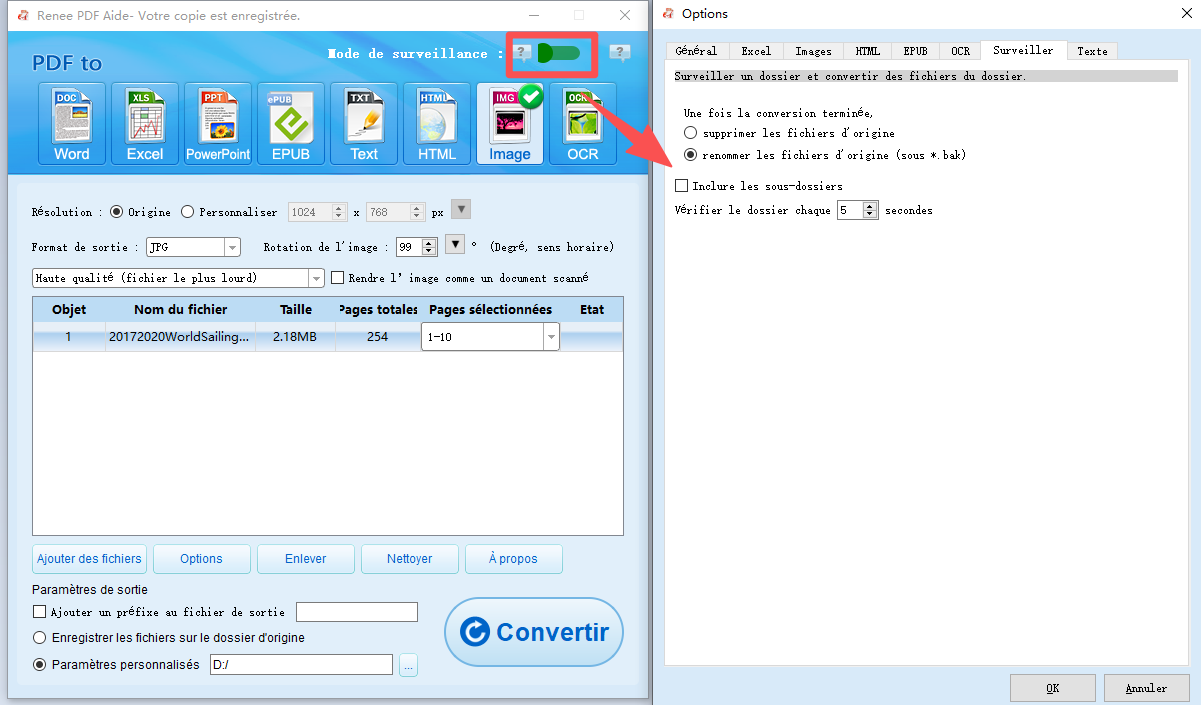
Conversions planifiées nocturnes | Mode surveillance de Renee PDF Aide |
Contrôle total du code + PDF simples | Script personnalisé PyMuPDF + watchdog |
Renee PDF Aide peut-il gérer les PDF numérisés que les scripts Python ne peuvent pas lire ?
Pourquoi pdf2docx perd-il la mise en forme de mes tableaux ou l’alignement des colonnes ?
Quelle est la taille maximale de lot ou la limite de pages dans Renee PDF Aide ?
Puis-je convertir des PDF protégés par mot de passe en DOCX avec Python ou Renee PDF Aide ?
Renee PDF Aide fonctionne-t-il avec les formulaires XFA (PDF bancaires/gouvernementaux) ?

Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Articles concernés :
Extraire Facilement des Tableaux PDF : Outils Gratuits et IA à Connaître

28-10-2025
Adèle BERNARD : Explorez les meilleures solutions gratuites et intelligentes pour extraire facilement des tableaux PDF en 2025. Convertissez vos fichiers...
Comment extraire le texte depuis un PDF?

03-10-2025
Louis LE GALL : Vous souhaitez extraire facilement le texte d’un PDF? Ce guide vous présente des méthodes simples et efficaces, des...


Commentaires des utilisateurs
Laisser un commentaire