Comment extraire des codes HTML depuis une image?

Résumé
Vous voulez extraire les codes HTML depuis une image mais n'arrivez pas à le faire? Ne vous vous inquiétez pas. Dans cet article, nous allons vous introduire quelques outils qui peuvent reconnaître et extraire les codes HTML depuis une image. Vous trouverez la résolution dans cet article.


Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Diverses fonctionnalités d’édition Chiffrer/Déchiffrer/Fusionner/Diviser/Ajouter un filigrane.
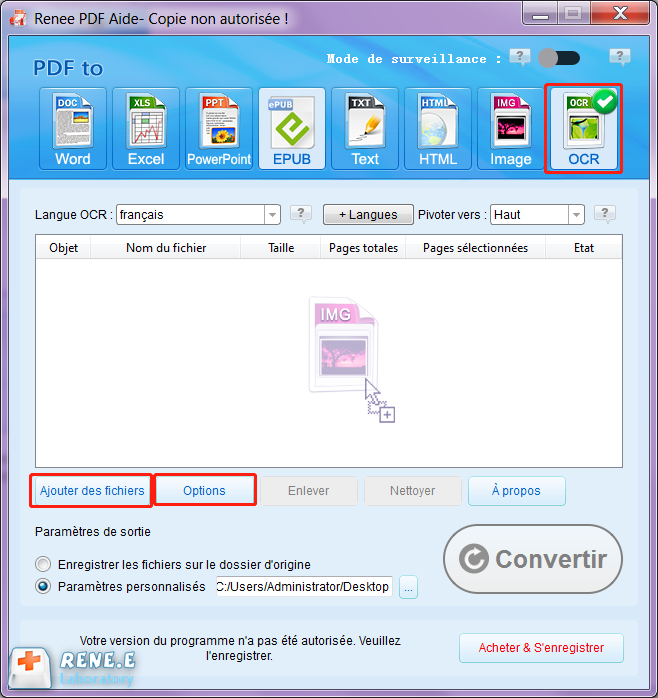
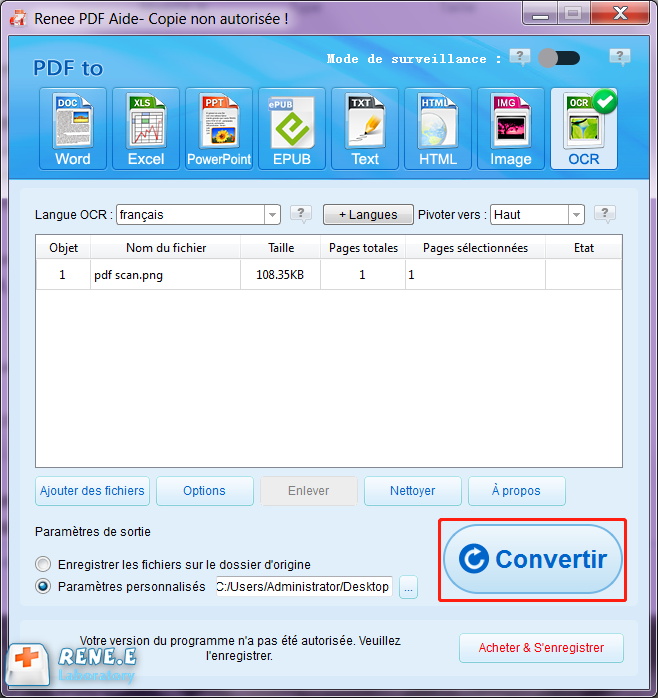
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Vitesse rapide d’édition et de conversion Editer et convertir simultanément plusieurs fichiers.
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Support de divers formats Convertir le fichier PDF en Word/Excel/PPT/Text/Html/Epub/Image/etc.
Fonction OCR : extrait le texte des PDF scannés, des images et des polices intégrées
Compatibilité : Windows 11/10/8/8.1/Vista/7/XP/2000
Articles concernés :
Convertir un fichier Word en PDF sous Microsoft Word
15-11-2017
Valentin DURAND : Avec Microsoft Office Word, vous pouvez très simplement convertir Word en PDF. Il suffit d'enregistrer le document Word...
Logiciel OCR gratuit pour extraire le texte d’une image

12-03-2024
Mathilde LEROUX : Pour obtenir un texte éditable depuis un document en papier, il est indispensable d'utiliser un logiciel OCR gratuit...
Commnent convertir un PDF en ePub gratuitement ?

11-08-2017
Adèle BERNARD : Pour avoir un ebook sous le format compatible avec toutes les liseuses électroniques, il suffit de convertir PDF...
Comment convertir un PDF en Excel gratuitement ?

15-11-2017
Louis LE GALL : Vous êtes en train de copier les chiffres d'un document PDF ou en papier en les saisissant un...

